














In our podcast episode, How to Succeed With BI: Types of Data Sources and Data Integration, Brick Thompson and Caleb Ochs get into the technical details around working with the various types of transactional data source connections you might encounter when building a data warehouse. They also discuss considerations for combining data from different source systems and for managing data duplicates and redundancy. Listen here, or on the player below.
Define the Impact and Start Small
This first step in a successful BI project is often overlooked but is critical (so much so that we’ve devoted a whole podcast episode to the topic). Define the impact of the project. What’s the return on investment? What’s the outcome you’re looking to improve? Where do things stand now, where do you want them to be, and by when? Also, how will you measure the ROI?
Companies should expect some degree of effort with data preparation and migration, and understanding the value and ROI, even a rough approximation of it, can help justify the effort. NewVantage Partners’ 2022 Data and AI Survey found that 92.1% of respondents reported measurable results from their data and AI investments (NewVantage, 2022); the effort will likely be worth it.
Next, while it’s tempting pull all available data sources into one data warehouse, both academic and the real-world practitioners of BI advise otherwise. Experts agree – with BI, it’s best to start small. Agile and lean approaches, which rely on short sprints and quick wins, are more effective for IT projects than traditional waterfall approaches (Ambysoft, 2013). This specifically applies to BI projects. Brick and Caleb recommend starting with one data source, realizing some quick wins, and then moving on to incorporating additional data sources as appropriate. You’ll learn a lot on the first one and that will create efficiencies on the ones that follow.
But starting small shouldn’t keep you from planning ahead. Users should consider potential future data needs, and the data warehouse should be built modular and scalable with a plan for accommodating future sources.
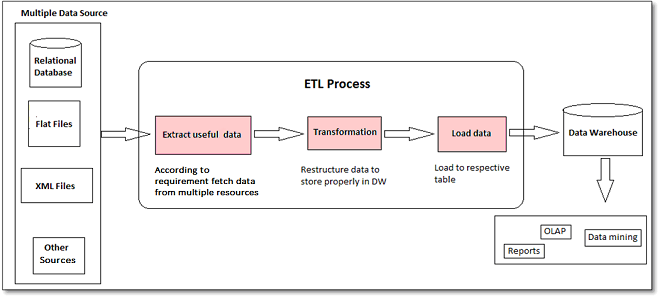 (Source: https://www.tatvasoft.com/blog/etl-process-extract-transform-load/)
(Source: https://www.tatvasoft.com/blog/etl-process-extract-transform-load/)
Next, consider your data sources.
Three Primary Transactional Data Source Scenarios for ETL
A data source is anything that houses data, but for the purposes of this article, we’re considering transactional software systems (e.g., ERP and CRM systems, etc.). There are three primary ways that you’ll access the data from these types of systems: connecting to a company managed Cloud or on-premises database, using an application programming interface (API), and connecting to a third-party software vendor-hosted database. These are listed roughly in order from in terms of ease of access.
Company Managed Cloud or On-Prem Database (generally easiest)
This type is owned by the company in a physical location, (i.e., a local server) or Cloud hosting service. The point is that it’s managed by the company, making access and control generally straightforward. This type could include Microsoft Azure VMs or SQL Servers, Amazon Web Services (AWS) VMs or Amazon Redshift databases, or an on-prem server. From the data architect’s perspective, this is the best case for access because it is generally easy to connect ETL tools to. The company has full control of the resource.
Application Programming Interface (API) (not bad)
This second type provides access to software’s data back-end-data through an application programming interface. APIs are common and are often a good option for connecting to a data source. However, we’ve seen cases where software companies deliver an unreliable or immature API, which can create challenges and delays. So when working with an API connection, it’s important to validate its maturity level and functionality so that you can make a plan for dealing with shortcomings. This sometimes involves contacting the software company for more detailed documentation, and even for requesting changes to the API.
Third Party Hosting (sometimes challenging)
This data source is not managed by the company, but rather by a third-party software provider. Setting up good ETL extracts from this type of system often involves significant upfront work with the software provider to deal with security and access issues. Plan accordingly in your project timeline.
Excel Spreadsheets (proceed with caution)
In addition to the sources above, clients often keep data in Excel spreadsheets (and sometimes even on paper!). This scenario requires a thorough quality assurance process for maintaining integrity of the data landing in the data warehouse. There are strategies for dealing with this, but the sooner you can move to getting this data into a more tightly governed storage system, the better.
Data Redundancy
Data redundancy is a common issue that happens when the same piece of data is held in two separate places (Techopedia, 2020). We often find multiple transactional data sources that have some relation to each other, such as an overlap of customer names, employee names, product names, etc. The same customer or employee may be entered into the different systems slightly differently which can make it difficult to know that they are actually referring to the same entity. Without good master data management or MDM (an important piece of data governance) to make sure the systems are kept in sync, reports may not summarize or roll up correctly.
MDM sometimes requires manual intervention by a company subject matter expert. They’ll use a tool to match entries to each other to tie records from the different systems together into conformed dimensions. The initial effort can be large, but then becomes a much smaller, ongoing, exceptions management process to keep things clean going forward.
With proper dimensional modeling and data visualization, a modeling tool will handle the relationship between the data entries and pull the right value for the reporting view. Caleb covers more technical detail around this at timestamp 18:29 of the podcast.
Technical Complexities Can Slow Progress
Technical challenges can cause slower progress toward digital transformation. Challenges with data quality, talent gap, wasted time, lack of proper tools and cost (SyncApps, 2022) contribute to slower culture transformation to becoming data-driven.
While the process of data source integration can be complex, doing it well leads to valuable insights and results for organizations. Consider hiring a partner to help you overcome the complexities of self-service BI. Blue Margin has 11+ years of experience helping 200+ clients overcome challenges on the journey to data driven, and while we’re able to serve as your virtual BI team, we’re also interested in training and supporting your team to manage future projects in-house.
If you’d like to explore how we might help you in your efforts, let’s connect!